无
”python kMeans“ 的搜索结果

各种聚类方法的python代码,包括k_means聚类以及实现过程


【资源说明】 实验目的 1、掌握K均值(k-means)聚类算法。 2、掌握学习向量量化(LVQ)聚类算法。 3、掌握高斯混合(Mixture-of-Gaussian)聚类算法。 4、理解聚类相关指标。...1、编写程序实现K均值(k-means)聚类...
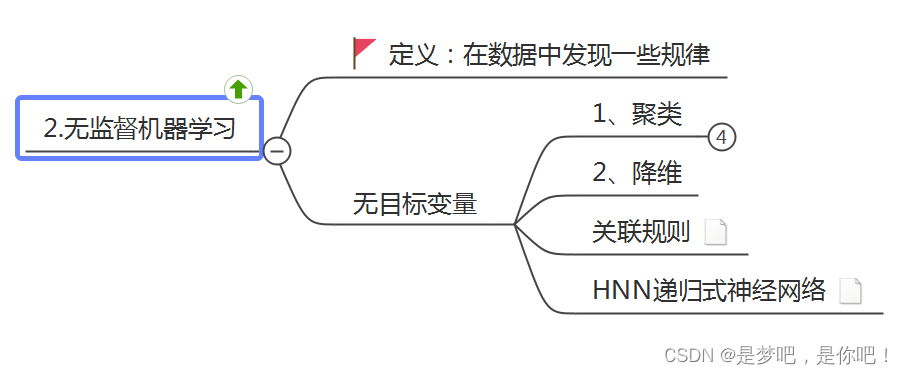
可以看到,当K=3时,产生了“肘点”,从K=3到K=4,SSE的下降速度明显变缓,因此最佳的K取值应为3。可以看到输出了所有样本的聚类标签,包括0-2,一共三个簇,同时输出了聚类平方误差总和。最后设置标签、添加图例,...

0.聚类聚类就是对大量的未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小,聚类属于无监督的学习方法。1.内在相似性的度量聚类是根据数据的内在的...
Python Kmeans聚类是一种基于距离的聚类算法,它将数据集分成k个簇,每个簇包含最接近其质心的数据点。该算法的目标是最小化簇内平方和,即最小化每个簇中数据点与该簇质心的距离的平方和。在Python中,可以使用...
这个Python的K-means聚类分析实例是使用K-means算法对数据进行聚类,并展示了聚类结果。首先,通过导入必要的库和数据源,我们读取了一个包含calories、sodium、alcohol和cost四个特征的数据集。...
在Python中,kmeans函数是用于执行聚类分析的函数。它的常用参数及其含义如下: 1. data:需要聚类的数据集。可以是一个二维数组,每一行代表一个数据点,每一列代表数据点的一个特征。 2. n_clusters:指定聚类的...
我理解您的问题是关于使用Python中的k-means聚类算法进行可视化的固定值问题。您可以使用matplotlib库来可视化聚类结果。具体来说,您可以使用scatter方法将聚类结果画在二维坐标系上,其中每个点的颜色表示其所属的...
您可以使用Python中的sorted函数对聚类结果进行排序,然后输出排序后的结果。例如,假设您的聚类结果存储在一个名为"clusters"的列表中,每个聚类分组为一个子列表。您可以使用以下代码将子列表中的元素按从小到大的...
一共两个例子,python3+k-means+matlab,我亲测,在python3.6环境下,可以使用。其他版本没测过。对初学者帮助不错,高手就不要点进来啦!有问题,咨询邮箱。记住一共两个例子,别混了
主要介绍了python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
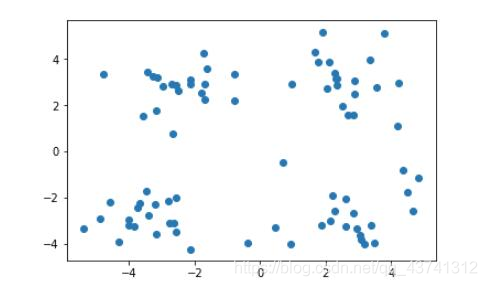
使用Kmeans分类算法,为各国体育水平分类。 体育竞赛数据使用1988年至2012年奥运会奖牌数据 一枚金牌得5分 一枚银牌得3分 一枚铜牌得1分 德国和俄罗斯比较特殊,东西德统一前,他们各自参赛,终究是一个民族,因此将...
主要为大家详细介绍了python kmeans聚类简单介绍和实现代码,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
主要为大家详细介绍了Python KMeans聚类问题,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
演示python kmeans图像压缩,代码较简单,有示例图片,需安装sklearn,numpy库


K-means算法的简介与Python3实现



聚类算法作为一种无监督学习方法其主要目的是将未标注的数据集中的样本划分为若干个不相干的子集,这些子集被称为簇(cluster)。聚类算法通过计算各个样本之间的相似性来将具有类似特征的的数据点划分到同一个簇中。...
推荐文章
- 【易飞】易飞ERP自动审核程序功能_易飞单据审批设置-程序员宅基地
- 青少年CTF擂台挑战赛 2024 #Round 1_xyctf高校新生联合赛 2024-程序员宅基地
- spring数据源配置:Tomcat/weblogic数据源切换配置_tomcat 数据库切换-程序员宅基地
- 计算机组成原理 之 计算题、分析题 题解详细总结(已完结)_计算机组成原理计算题-程序员宅基地
- react-native 0.57 版本更新日志-程序员宅基地
- 【IDEA&Eclipse快捷键对照表】_eclipse的folder对应idea的哪个-程序员宅基地
- 修改pycharm目录后,无法打开的问题!!!_为什么修改已安装的pycharm的安装路径会打不开软件-程序员宅基地
- labview中visa插件安装教程_nivisa安装教程-程序员宅基地
- matlab快速入门(7):创建等间距向量_matla间隔相等的向量-程序员宅基地
- Git的相关操作,创建、更新、提交等,代码托管在码云上_使用git提交代码,git commit -m ' ' 提交、同步代码之后,在码云上备注是乱码。怎-程序员宅基地